Overview
While working with the Jet Data Manager, you will come across the terms "deployment" and "execution". These words describe the process by which data structures are created and populated. The following is an in-depth look at what happens during the deployment and execution process. This article covers the following:
What is Deployment?
A database object (table, stored procedure, view, etc...) does not exist until it is deployed. Deploying an object simply means to create or bring the object into existence.
What Objects are Created During the Deployment Process?
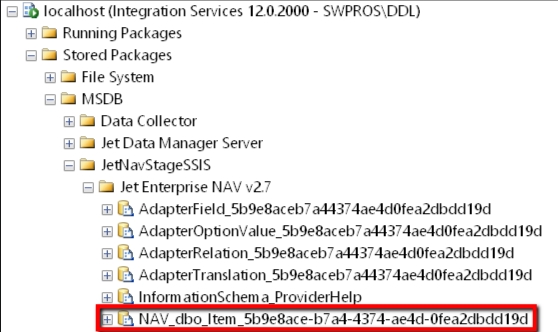
There are many different objects that are created during the deployment process. Let's demonstrate this using an example:
Let's choose the Item table and perform a deploy
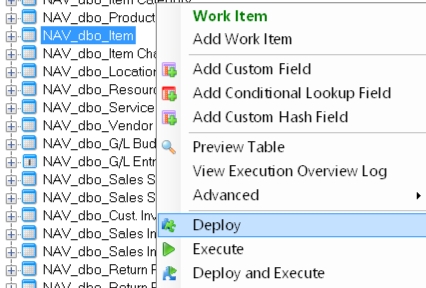
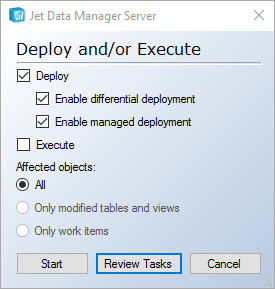
A selection window will appear with a Start button to begin and a Review Tasks button to show all steps before beginning the deployment.
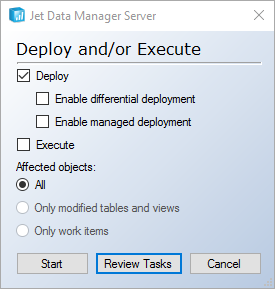
Notice that there are several steps. Each one of these steps represents the creation of an object within the database.
-
Deploy <Database Name> <Table Name> Raw Table Structure
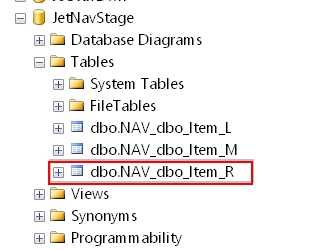
This step creates the _R (RAW) table. This table contains the records as they where extracted from the data source.
-
Deploy <Database Name> <Table Name> Error List Table Structure
This step creates the _L (LOG) table. This table is used to log the error number generated by the application.
 This table will generally be empty.
This table will generally be empty. -
Deploy <Database Name> <Table Name> Message Table Structure
This step creates the _M (MESSAGE) table. This table will contain error messages generated by the application that relate to the _L table referenced above.
This table will generally be empty -
Deploy <Database Name> <Table Name> Transformation View
This step creates the _T (TRANSFORMATION) table. This is an intermediate table where the data is altered during the data cleansing process.
-
Deploy <Database Name> <Table Name> Valid Table Structure
This step creates the _V (VALID) table. This table contains the records as they are after the data cleansing and data quality process has executed.
-
Deploy <Database Name> <Table Name> SSIS Transfer Package
This step creates the SQL Server Integration Services package that will be used to transfer data during the execution phase.
-
Deploy <Database Name> <Table Name> Data Cleansing Rules
This step creates a stored procedure that will perform the data cleansing.
Differential & Managed Deployment
-
Differential Deployment
Differential deployment is a more efficient way of deploying parts of your project without deploying everything; it is based on the idea that there is no need to deploy something that has already been deployed.
Each object in the Jet Data Manager can have many underlying objects in SQL Server. For instance, a table in a Jet Data Manager project can have a raw and a valid table instance. On top of that, there is an error table, a log table, an incremental table, a transformation view, a SSIS package and a data cleansing procedure.
When a transformation is changed or added on a field, all that needs to be deployed is the transformation view. If a new lookup field is added to a table, all that needs to be deployed are the raw table, the valid table, and the data cleansing procedure. The rest of the objects do not require any deployment.
Differential deployment is available for objects on the Data tab in Jet Data Manager and enabled by default on new projects. To change the default setting, right-click the project node, click on Project Settings and change the setting for Enable Differential Deployment. You can turn differential deployment on or off for a single deployment in the new Deploy/execute Setup window.
The differential deployment feature is also available when you deploy on a remote environment.
-
Managed Deployment
The Jet Data Manager has supported managed execution that, among other things, manages dependencies for you. In this release, we have used some of the same ideas to improve deployment.
The Jet Data Manager will take all dependencies it knows into account to make sure that objects are deployed in the correct order. It can calculate the dependencies of views, stored procedures, and user-defined functions by looking at the objects that are referenced in the scripts. It will also deploy a table that has a lookup field after the table that is the source of the lookup field. You can add dependencies you want the Jet Data Manager to take into account. In addition to being able to define table dependencies, you can now define dependencies between tables, views, stored procedures, user-defined functions and any combination of those objects.
-
Deployment Status Report
Using the new differential deployment feature, Jet Data Manager lets you export a deployment status report that contains a list of what needs to be deployed. You can generate the report for projects, data warehouses, business units, and OLAP servers. You can also generate the report for a remote environment. The report can be formatted as a CSV file or exported as a PDF.
To generate a deployment status report for a project, data warehouse, business unit or OLAP server, right click on the object, click on Advanced and click on Export Deployment Status.
To generate a deployment status report for a remote environment, open Multiple Environment Transfer, right click on the remote environment and click on Export Deployment Status.
The Jet Data Manager will ask you to choose a location for the file. When the report has been successfully generated, Jet Data Manager will ask you if you want to open it.
What is Execution?
An object is empty (contains no data) until it is executed. Execution is the process of populating and cleansing our objects (tables, view, cubes, dimensions) with data.
What Happens During the Execution Process?
To demonstrate what happens during the execution process let's execute the Item table.
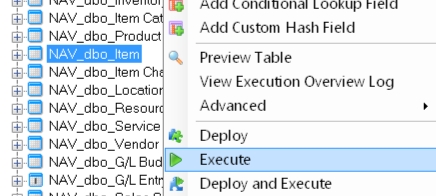
A selection window will appear with a Start button to begin and a Review Tasks button to show all steps before beginning the execution.
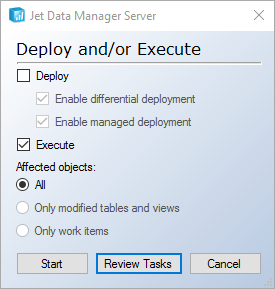
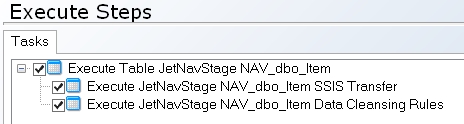
The execution phase has two steps
-
Execute <Database Name><Table Name> SSIS Transfer
This step is tasked with moving (transferring) data. For example it will move data from the source and populate the _R table.
-
Execute <Database Name><Table Name> Data Cleansing Rules
This step will execute the stored procedure created during the deployment phase. It is this step that performs the cleansing of the data using the _T table and will then move the data into the _V table if a physical table is being used for this.
Comments