Overview
Incremental loading allows an organization to only load the most recent transactional data into their data warehouse and staging databases, in order to facilitate faster load times. This can be beneficial when the volume of transactional data in the data source causes scheduled execution times to take longer than desired. Incremental loading can also help facilitate more reasonable execution times when multiple updates throughout the day are desirable.
Full Load Process
The default load plan during scheduled execution is a Full Load. During a full load all of the tables and fields that are used in a project are completely refreshed and the full data set is moved from the data source to the staging database and data warehouse. During the full load process, the existing tables in the staging database and data warehouse are truncated - which removes all of the existing data first and then the new data is subsequently loaded from the data source.
Incremental Load Process
During the incremental load process, the Jet Data Manager looks at fields that are defined by the user in order to automatically determine the amount of data that will be moved over. During the first deployment after incremental loading has been enabled, the Jet Data Manager will create additional tables in the staging database and data warehouse that have a _INCR suffix. The Jet Data Manager will then do a full load to bring over all of the required data from the data source. During subsequent execution of the project, truncation is disabled on these tables so that the original data is not removed. The Jet Data Manager then determines which records have been added to the data source since the last load and only transfers these new records to the appropriate tables in the staging database and data warehouse. This can drastically cut down on the amount of time necessary for execution of the objects in the project.
Does My Organization Need Incremental Loading Enabled?
A common misconception is that candidacy for incremental loading is directly dependent on the size of the data source (NAV, GP, AX, etc.). The best indicator as to whether or not incremental loading should be enabled is not the amount of data that needs to be transferred, but is actually the amount of time that it takes to transfer the data. Every organization has unique environments in which the Jet Data Manager is installed. One organization may experience an execution time of 30 minutes to transfer 50gb of data while another organization may experience only 10 minutes to transfer the same amount, or be able to transfer a much larger volume of transactional data in the same 30 minutes. Once the amount of time required to perform a full load begins to run longer than the organization feels is acceptable regarding their execution strategy (nightly updates, multiple updates throughout the day, etc.) then incremental loading becomes a viable option.
How to Enable Incremental Loading
The first step in setting up an incremental loading plan is to identify those tables which should have incremental loading enabled. Most smaller or summary level tables such as Customer, Item, and G/L Account tables will not generally impact performance, as they will not have a substantial number of records. The tables that are candidates to have incremental loading enabled will be larger transaction tables such as those that contain large volumes of general ledger and inventory transactions. The examples used in this document will use the G/L Entry table from Dynamics NAV, however the concepts are universal and apply to all data sources.
Enabling Incremental Loading for Staging Database Tables
-
To enable incremental loading for tables in the staging database, you will first need to go to the table in the staging database, right-click the table name, and select Table Settings
-
On the Data Extraction tab, check the box for Enable source based incremental load. Click OK to continue.
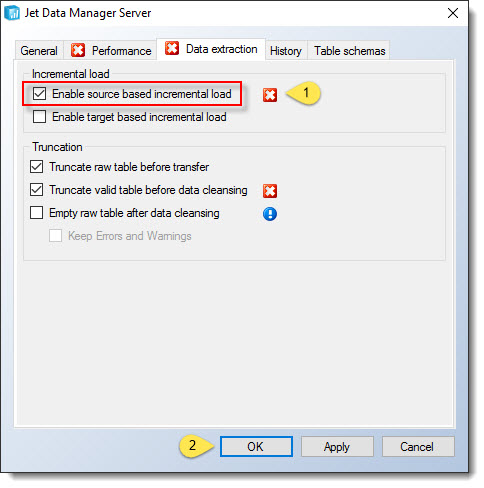
If a red X denoting an error appears near the Physical Valid Table checkbox on the Performance tab, it means that this box must be checked in order to use incremental loading on this table. Check the box for Physical Valid Table prior to clicking OK.
Similarly, if a red X appears under the Truncation settings, it means that this box must be unchecked to proceed.
-
The table icon in the staging database will now have an “I” icon identifying it as an incrementally loaded table.
In order for incremental loading to be successful, the table must have a primary key defined. In all of the Jet Analytics projects available for download on the CubeStore, the most common tables used with incremental loading already have the proper primary keys defined. To define a field or fields to be used as the primary key for the table, right-click the field name and select Include in Primary Key.
It is very important that primary keys are defined correctly! If you are not sure about which fields comprise the correct primary key for a table, consult with your ERP software provider or contact a member of the Jet Reports team. -
Locate the table in the Data Source section at the bottom of the Data tab. Right-click the table name and select Add Incremental Selection Rule .
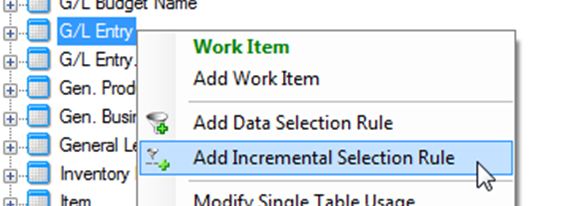
Check the box or boxes that mark the fields that will identify which records have been added or changed since the last incremental load. These will ideally be fields that are generated by the system and incremented sequentially when new records are added.
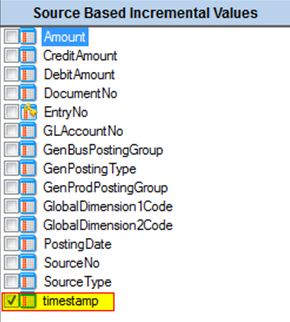
In Dynamics NAV, the timestamp field is generally regarded as the best selection. When records are added or updated, this field is updated in the data source - which will always flag these as records that need to be added or updated by the Jet Data Manager.
In Dynamics GP, the DEX_ROW_ID field is generally regarded as the best selection. This field is automatically incremented by GP when new records are added.
In Dynamics AX the Modified_Datetime field is generally regarded as the best selection. This functionality may need to be enabled on a table-by-table basis in AX, in order for it to appear. Please contact your AX partner for help on configuring this if necessary.
Repeat the steps above for all tables to which incremental loading will be enabled.
If the table that you are setting up for Incremental Loading is the source for lookups on other tables, it is very important that you disable automatic index creation. For more information, please read Disabling Automatic Indexing in the Jet Data Manager -
Right click the Business Unit and select Deploy and Execute -> Deploy and Execute Modified Object.
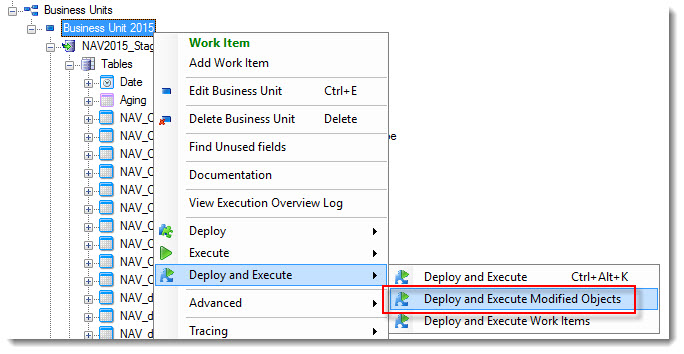
Click the Start button to initiate the first full load of the tables with source based incremental loading now enabled.
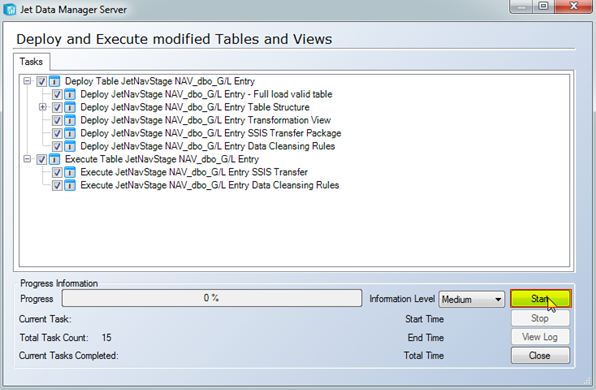
The necessary incremental tables will be automatically added to the staging database and populated with the latest incremental values. The next time that the table is executed, the Jet Data Manager will query these tables to determine the last record that was previously loaded and will only extract data from the data source that occurred since the last execution.
Using the Incremental Load Wizard
When you have more than a trivial amount of data in a table, incremental load becomes incredibly useful. While setting up incremental load for a single table is fast and easy, it can be a time-consuming task to implement in multiple tables. In Jet Data Manager 2017 and higher, you can set up incremental load for any number of tables in a wizard-style interface.
To access the wizard right click on the applicable data source, go to Automate, and select Set Up Incremental Load:

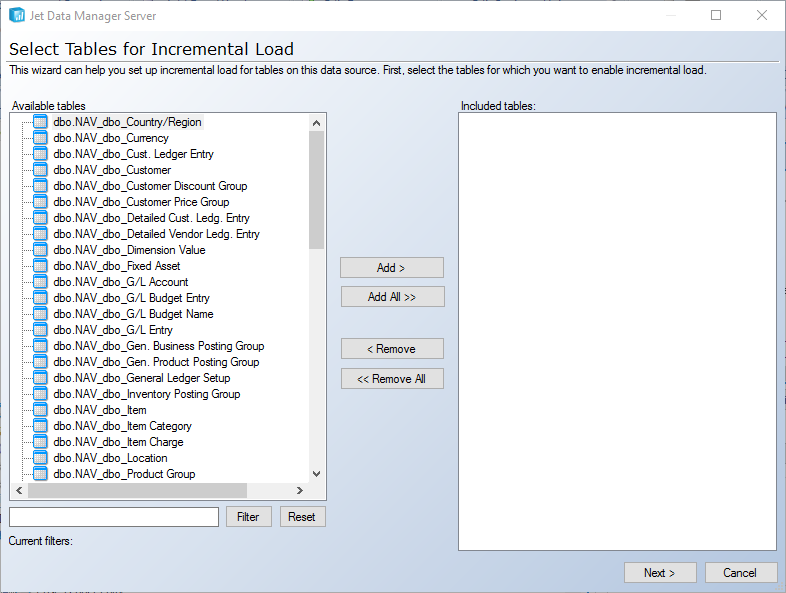
Select the tables you want to load incrementally, select primary key fields, and set your data selection rules. Jet Data Manager will then apply your selections. Combined with the easier application of primary key suggestions in JDM 2017 and higher, setting up incremental load in a large number of tables is a very simple process.
Enabling Incremental Loading for Data Warehouse Tables
-
In the staging database, right-click the table that you previously configured to use incremental loading. Navigate to Advanced → Show System Control Fields .
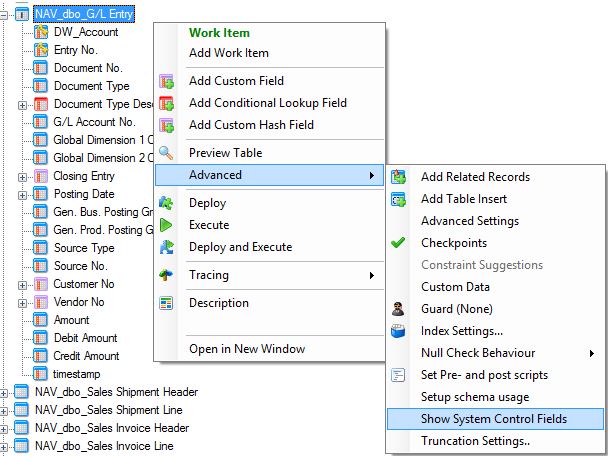
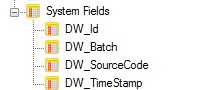
Notice that a series of system generated fields have been added to the bottom of the table.
-
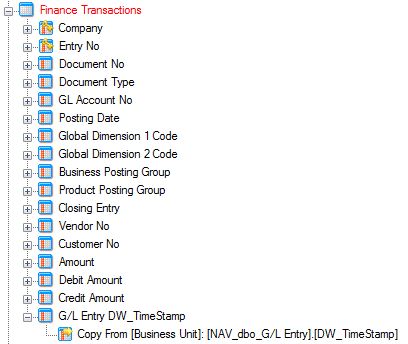
Grab the DW_TimeStamp field and bring it to the table in the data warehouse where you wish to implement incremental loading.
In this example, we moved the DW_TimeStamp field from the G/L Entry table to our Finance Transactions table.
-
In the data warehouse, right-click the table for which you wish to implement incremental and select Table Settings .
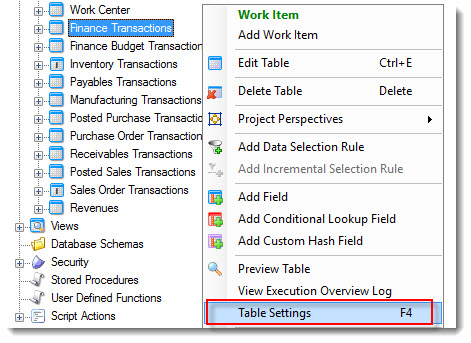
-
Check the box for Source based incremental load. Click OK .
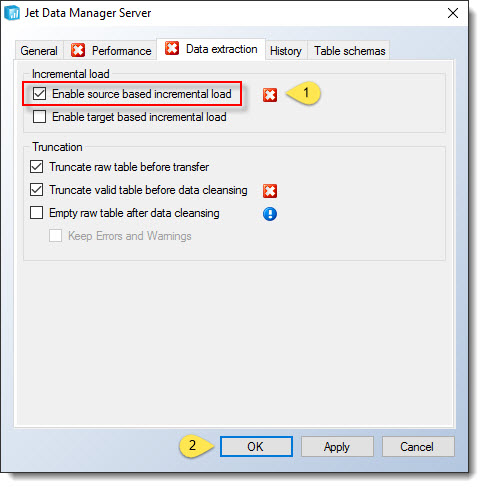 If a red X denoting an error appears near the Physical Valid Table checkbox, it means that this box must be checked in order to use incremental loading on this table. If the red X is near the truncation settings, it means this box must be unchecked to continue.
If a red X denoting an error appears near the Physical Valid Table checkbox, it means that this box must be checked in order to use incremental loading on this table. If the red X is near the truncation settings, it means this box must be unchecked to continue. -
Next, right,click the table and click Add Incremental Selection Rule.
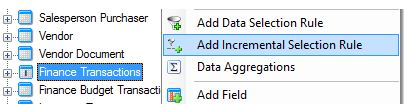
Select the system generated timestamp field that we previously added to the table.
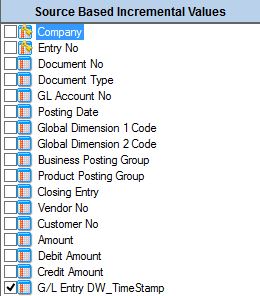
-
After you select the field to use in the incremental loading selection rule, you then need to make sure your data warehouse table has a primary key set. This will be indicated by a gold key. If your table does not have a primary key setup you will need to make one.
There are two options. The first option is to identify the primary key for that table in the data source, bring that field up into the data warehouse, and then set it as the primary key. -
The second option would be to use the fields that already exist in the table. If there isn't a single field which can serve as a unique identifier, you can set more than one field as a primary key and the combination of those fields will result in a unique ID.
To set a field as a primary key in the data warehouse, just right click on the field and choose Include in Primary Key. The field will then have a little gold key on it (see below). Then you can Deploy and Execute without an error.

 If the table that you are setting up for Incremental Loading is the source for lookups on other tables, it is very important that you disable automatic index creation. For more information, please read Disabling Automatic Indexing in the Jet Data Manager
If the table that you are setting up for Incremental Loading is the source for lookups on other tables, it is very important that you disable automatic index creation. For more information, please read Disabling Automatic Indexing in the Jet Data Manager -
Right-click the data warehouse node and select Deploy and Execute -> Deploy and Execute Modified Objects .
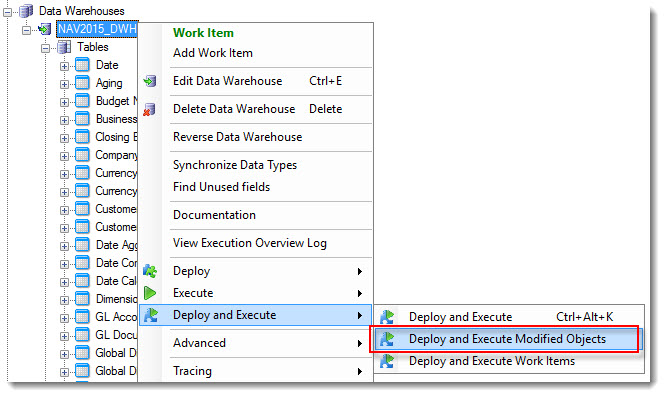
Click Start.
 If the table for which you are attempting to setup incremental loading has multiple data movements, you will need to add the system generated DW_TimeStamp field for each data movement associated with the table.
If the table for which you are attempting to setup incremental loading has multiple data movements, you will need to add the system generated DW_TimeStamp field for each data movement associated with the table.
Handling of Deleted Records
If you use incremental load on a data source, and records are deleted, the tables in your data warehouse can quickly become out of sync with the data source.
In versions of Jet Data Manager prior to v17.1, you handle this by scheduling a periodic full load of the table combined with (if necessary) a script to remove any records deleted in the data source on each incremental load. In Jet Data Manager 17.1 and higher, automated delete handling is available as an option on incrementally loaded tables.
To turn on Automated Delete Handling, right-click on the incrementally loaded table and select Table Settings, then go to the Date Extraction tab:

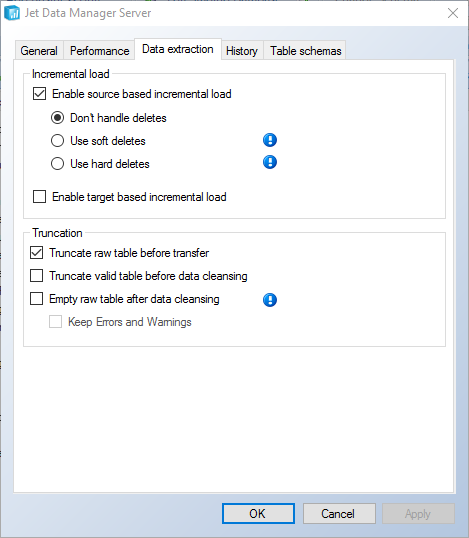
In addition to the traditional behavior (Don’t Handle Deletes), versions v17.1 and higher also provide the choice between:
Hard deletes - where the records deleted in the data source are also deleted in the valid instance, and
Soft deletes - where the records are just marked as deleted in the valid instance.
The feature is implemented as shown in the figure below:

On each incremental load, data is extracted from the source and into two instances of the table. The raw instance contains all the new records, while the primary key (“PK”) instance contains the content of the primary key columns for all records. Once the data has been transferred from raw to valid through the transformation view, Jet Data Manager will delete any record in the valid instance that has a primary key that cannot be found in either the raw or the PK instance. If soft delete is enabled, Jet Data Manager will add a column (“Is tombstone”) to the valid instance and updated deleted records with the value “true”.
The implementation is designed to be fast and simple. At the same time, it provides a good infrastructure to handle more advanced use cases. e.g.:
- If a record is undeleted/restored in the source, Jet Data Manager will not undelete it in the valid instance, unless it is loaded into the raw table again. So, depending on your situation, you could build a simple post script onto the data cleansing to raise the dead records with a simple update of the valid instance based on the PK instance.
- If a primary key is transformed from raw to valid, Jet Data Manager will not be able to match it to the primary keys stored in the raw and PK instance. If this transformation is to be taken into account when looking for deleted records, consider placing the transformation in a prescript. Sometimes, you might not know if you can expect records to be deleted in a data source; the new options make it easy to test. Simply enable soft deletes for the table and see if tomb stoned records begin to appear.
Comments